简介 Facebook的数据仓库存储在少量大型Hadoop/HDFS集群。Hive是Facebook在几年前专为Hadoop打造的一款数据仓库工具。在以前,Facebook的科学家和分析师一直依靠Hive来做数据分析。但Hive使用MapReduce作为底层计算框架,是专为批处理设计的。但随着数据越来越多,使用Hive进行一个简单的数据查询可能要花费几分到几小时,显然不能满足交互式查询的需求。Facebook也调研了其他比Hive更快的工具,但它们要么在功能有所限制要么就太简单,以至于无法操作Facebook庞大的数据仓库。
2012年开始试用的一些外部项目都不合适,他们决定自己开发,这就是Presto。2012年秋季开始开发,目前该项目已经在超过 1000名Facebook雇员中使用,运行超过30000个查询,每日数据在1PB级别。Facebook称Presto的性能比Hive要好上10倍多。2013年Facebook正式宣布开源Presto。
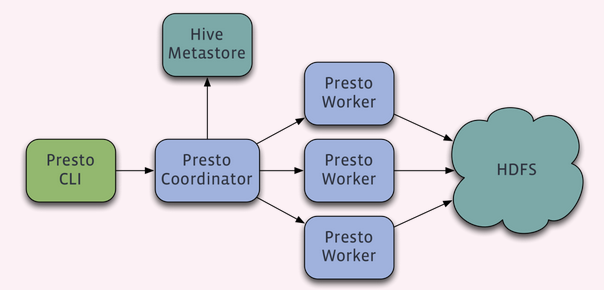
Presto查询引擎是一个Master-Slave的架构,由一个Coordinator节点,一个Discovery Server节点,多个Worker节点组成,Discovery Server通常内嵌于Coordinator节点中。Coordinator负责解析SQL语句,生成执行计划,分发执行任务给Worker节点执行。Worker节点负责实际执行查询任务。Worker节点启动后向Discovery Server服务注册,Coordinator从Discovery Server获得可以正常工作的Worker节点。如果配置了Hive Connector,需要配置一个Hive MetaStore服务为Presto提供Hive元信息,Worker节点与HDFS交互读取数据。
*特点
完全基于内存的并行计算
流水线
本地化计算
动态编译执行计划
小心使用内存和数据结构
类BlinkDB的近似查询
GC控制
*提交查询
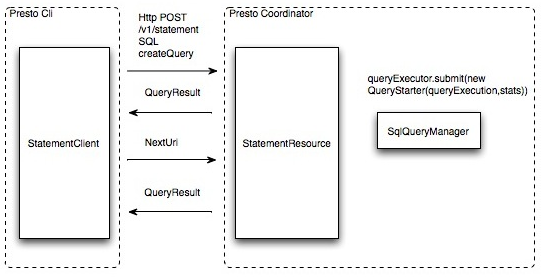
用户使用Presto Cli提交一个查询语句后,Cli使用HTTP协议与Coordinator通信,Coordinator收到查询请求后调用SqlParser解析SQL语句得到Statement对象,并将Statement封装成一个QueryStarter对象放入线程池中等待执行。
http://showterm.io/
环境要求 基本要求:
Linux or Mac OS X
Java 8, 64-bit
Python 2.4+
HADOOP / HIVE Presto supports reading Hive data from the following versions of Hadoop:
Apache Hadoop 1.x
Apache Hadoop 2.x
Cloudera CDH 4
Cloudera CDH 5
The following file formats are supported: Text, SequenceFile, RCFile, ORC
Additionally, a remote Hive metastore is required. Local or embedded mode is not supported. Presto does not use MapReduce and thus only requires HDFS.
CASSANDRA Cassandra 2.x is required. This connector is completely independent of the Hive connector and only requires an existing Cassandra installation.
TPC-H The TPC-H connector dynamically generates data that can be used for experiementing with and testing Presto. This connector has no external requirements.
Deployment 一、安装和部署Presto 1、安装环境 1 2 3 4 5 6 7 8 9 10 11 12 13 14 # 操作系统 CentOS release 6.5 (Final) 2.6.32-431.el6.x86_64 #1 SMP Fri Nov 22 03:15:09 UTC 2013 x86_64 x86_64 x86_64 GNU/Linux # Hadoop版本 Hadoop 2.4.0 # hive版本 hive-0.13.1 #XXk版本 java version "1.8.0_45" export PATH=.:$JAVA_HOME/bin:$PATH export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib:$CLASSPATH
2、presto架构
上图可以看到,需要依赖hivemetastor服务,访问hive里面的表!所以一定需要安装hive并且启动hivemetasotre服务!
3、安装presto 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 https://prestodb.io/docs/current/installation.html https://repo1.maven.org/maven2/com/facebook/presto/presto-server/0.100/presto-server-0.100.tar.gz #解压 tar -zxvf presto-server-0.103.tar.gz #创建软连接 ln -s presto-server-0.103 presto #解压后目录 [root@server1 presto]# tree -L 2 . |-- NOTICE |-- README.txt |-- bin | |-- launcher | |-- launcher.properties | |-- launcher.py | `-- procname |-- lib | |-- aether-api-1.13.1.jar | |-- ……… `-- plugin |-- cassandra |-- example-http |-- hive-cdh4 |-- hive-cdh5 |-- hive-hadoop1 |-- hive-hadoop2 |-- kafka |-- ml |-- mysql |-- postgresql |-- raptor `-- tpch Plugin中可以看到支持hadoop1,hadoop2,cdh5,cdh4这些插件,下面我们用到的是hive-hadoop2
4. 配置 Presto 1 2 3 4 5 6 在presto-server-0.100里面创建etc目录,并创建以下文件: node.properties:每个节点的环境配置 jvm.config:jvm 参数 config.properties:配置 Presto Server 参数 log.properties:配置日志等级 Catalog Properties:Catalog 的配置
(1).etc/node.properties 示例配置如下 1 2 3 4 5 6 7 8 node.environment=production node.id=5b47019c-a05c-42a5-9f9c-f17dbe27b42a #这个值必须是唯一的 node.data-dir=/usr/local/presto/data 参数说明: node.environment:环境名称。一个集群节点中的所有节点的名称应该保持一致。 node.id:节点唯一标识的名称。这里使用uuidgen生成。 node.data-dir:数据和日志存放路径。
(2).etc/jvm.config 示例配置如下 1 2 3 4 5 6 7 8 9 10 11 12 13 14 -server -Xmx16G -XX:+UseConcMarkSweepGC -XX:+ExplicitGCInvokesConcurrent -XX:+CMSClassUnloadingEnabled -XX:+AggressiveOpts -XX:+HeapDumpOnOutOfMemoryError -XX:OnOutOfMemoryError=kill -9 %p -XX:ReservedCodeCacheSize=150M #-Xbootclasspath/p:/home/hsu/presto/lib/floatingdecimal-0.1.jar,1.7打patch,1.8不在需要! -Djava.library.path=/opt/cloudera/parcels/CDH-5.2.0-1.cdh5.2.0.p0.36/lib/hadoop-0.20-mapreduce/lib/native/Linux-amd64-64 需要注意的是最后两行: /usr/local/presto/Linux-amd64-64:这是为了在Presto中支持LZO
(3).etc/config.properties 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 etc/config.properties包含 Presto Server 相关的配置,每一个 Presto Server 可以同时作为 coordinator 和 worker 使用。你可以将他们配置在一个节点上,但是,在一个大的集群上建议分开配置以提高性能。 coordinator 的最小配置: coordinator=true node-scheduler.include-coordinator=false http-server.http.port=9090 task.max-memory=1GB discovery-server.enabled=true discovery.uri= http://server1:9090 worker 的最小配置: coordinator=false http-server.http.port=9090 task.max-memory=1GB discovery.uri= http://server1:9090 可选的,作为测试,你可以在一个节点上同时配置两者: coordinator=true node-scheduler.include-coordinator=true http-server.http.port=9090 task.max-memory=1GB discovery-server.enabled=true discovery.uri=http://server1:9090 参数说明: coordinator:Presto 实例是否以 coordinator 对外提供服务 node-scheduler.include-coordinator:是否允许在 coordinator 上进行调度任务 http-server.http.port:HTTP 服务的端口 task.max-memory=1GB:每一个任务(对应一个节点上的一个查询计划)所能使用的最大内存 discovery-server.enabled:是否使用 Discovery service 发现集群中的每一个节点。 discovery.uri:Discovery server 的 url
(4).etc/log.properties 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 etc/log.properties 可以设置某一个 java 包的日志等级: com.facebook.presto=INFO 关于 Catalog 的配置,首先需要创建 etc/catalog 目录,然后根据你想使用的连接器来创建对应的配置文件,比如,你想使用 jmx 连接器,则创建 jmx.properties: connector.name=jmx 如果你想使用 hive 的连接器,则创建 hive.properties: connector.name=hive-hadoop2 hive.metastore.uri=thrift://server2:9083 #修改为 hive-metastore 服务所在的主机名称,这里我是安装在 server2节点 hive.config.resources=/usr/local/hadoop-2.4.0/etc/hadoop/core-site.xml, /usr/local/hadoop-2.4.0/etc/hadoop/hdfs-site.xml hive.allow-drop-table=true #允许删除hive表 更多关于连接器的说明,请参考 http://prestodb.io/docs/current/connector.html。 通过以上的四步,Coordinator已经设置完毕。
(5).配置worker节点 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 所有的配置的目录结构都是一样的,只需要修改上述的两个文件就可以达成Workers上的统一配置: scp -rq presto server3:/usr/local/ 修改第一个文件:config.properties: coordinator=false http-server.http.port=9090 task.max-memory=1GB discovery.uri=http://server1:9090 我们看到,作为Worker节点,已经将coordinator禁用掉:coordinator=false; PrestoServer的监听地址,还是9090端口; 单任务内存数还是1GB; 指向我们的DiscoveryServer:discovery.uri= http://server1:9090 修改第二个文件:node.properties node.environment=production node.id=c0550bd7-fcc2-407d-bfda-b1f26fb341b0 node.data-dir=/usr/local/presto/data 除了node.id的配置修改外,其它都保持一致即可,这个ID需要每个节点都不同,所以,这个不能简单的拷贝到其它Worker节点上,而要在每个节点上都修改成一个独一无二的值,我这里是通过uuidgen这个命令来生成的这个串。
(6). 添加对LZO的支持 1 2 3 4 5 6 7 8 9 1. 我们需要在每个Presto节点上的对应的插件目录下,放置hadoop-lzo.jar文件,以使其运行时可以加载到相关类: cd /usr/local/presto/plugin/hive-hadoop2 scp -r hadoop-lzo.jar itr-node0x:/usr/local/presto/plugin/hive-hadoop 2. JVM启动参数中,添加如下参数: -Djava.library.path=/usr/local/presto/Linux-amd64-64 这样,HDFS中的LZO文件就可以正常访问到了。
(7). 关于性能的一些测试经验 1 2 如果不禁止Coordinator上运行任务(node-scheduler.include-coordinator=false),那么性能的降低也非常明显。 node-scheduler.include-coordinator:是否允许在coordinator服务中进行调度工作。对于大型的集群,在一个节点上的Presto server即作为coordinator又作为worke将会降低查询性能。因为如果一个服务器作为worker使用,那么大部分的资源都不会被worker占用,那么就不会有足够的资源进行关键任务调度、管理和监控查询执行。
5、连接器配置 5.1 presto支持的连接器
(1). Black Hole Connector
(2). Cassandra Connector
(3)·. Hive Connector
(4). JMX Connector
(5). Kafka Connector
(6). Kafka Connector Tutorial
(7). MySQL Connector
(8). PostgreSQL Connector
(9). System Connector
(10). TPCH Connector
5.2 hive 1 2 3 4 5 6 7 8 9 10 11 关于 Catalog 的配置,首先需要创建 etc/catalog 目录,然后根据你想使用的连接器来创建对应的配置文件,比如,你想使用 jmx 连接器,则创建 jmx.properties: connector.name=jmx 如果你想使用 hive 的连接器,则创建 hive.properties: connector.name=hive-hadoop2 hive.metastore.uri=thrift://server2:9083 #修改为 hive-metastore 服务所在的主机名称,这里我是安装在 server2节点 hive.config.resources=/usr/local/hadoop-2.4.0/etc/hadoop/core-site.xml, /usr/local/hadoop-2.4.0/etc/hadoop/hdfs-site.xml hive.allow-drop-table=true #允许删除hive表 更多关于连接器的说明,请参考 http://prestodb.io/docs/current/connector.html。
5.3 mysql 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 $ cat mysql.properties connector.name=mysql connection-url=XXbc:mysql://server1:3306 connection-user=root connection-password=admin $ /home/hsu/presto/bin/presto-cli --server server1:9090 --catalog mysql --schema mysql; presto:mysql> SHOW TABLES FROM mysql.hive; presto:default> SHOW SCHEMAS; presto:default> use hive; presto:hive> show tables; $ /home/hsu/presto-server-0.103/bin/presto-cli --server server1:9090 --catalog mysql --schema airpal presto:default> SHOW SCHEMAS; Schema -------------------- airpal presto:default> show catalogs; Catalog --------- hive system jmx mysql (4 rows) 如果遇到查看mysql数据 presto:airpal> select * from jobs; Query 20150521_062342_00051_ueeai failed: No nodes available to run query 1、检查mysql是否在presto的主节点 2、检查主节点配置文件cat config.properties是否配置node-scheduler.include-coordinator=false,打开即可解决 3、禁止了主节点worker,那就无法读取到mysql数据! #写数据mysql到hive presto:default> show catalogs; Catalog --------- hive system jmx tpch mysql (5 rows) presto:default> create table hive.default.jobs as select * from mysql.airpal.jobs; CREATE TABLE: 10 rows Query 20150521_083025_00038_z2qr2, FINISHED, 2 nodes Splits: 3 total, 3 done (100.00%) 0:03 [10 rows, 0B] [3 rows/s, 0B/s] presto:default> select count(1) from jobs; _col0 ------- 10 (1 row)
5.4 kafka 这里主要参考官网实现:https://prestodb.io/docs/current/connector/kafka-tutorial.html
Step 1: Install Apache Kafka
Step 2: Make the Kafka topics known to Presto1 2 3 4 5 6 $ cat kafka.properties connector.name=kafka kafka.nodes=server1:9092,server2:9092,server3:9092 kafka.table-names=tpch.customer,tpch.orders,tpch.lineitem,tpch.part,tpch.partsupp,tpch.supplier,tpch.nation,tpch.region kafka.hide-internal-columns=false #需要重启集群
Step 3: Load data1 2 3 4 5 6 7 http://prestodb-china.com/docs/current/connector/kafka-tutorial.html $ curl -o kafka-tpch https://repo1.maven.org/maven2/de/softwareforge/kafka_tpch_0811/1.0/kafka_tpch_0811-1.0.sh $ mv kafka_tpch_0811-1.0.sh kafka_tpch $ chmod 775 kafka_tpch $ ./kafka_tpch load --brokers server1:9092 --prefix tpch. --tpch-type tiny
Step 4: Basic data querying1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 $ ../bin/presto-cli --server server1:9090 --catalog kafka --schema tpch presto:tpch> show tables; Table ---------- customer lineitem nation orders part partsupp region supplier (8 rows) presto:tpch> DESCRIBE customer; Column | Type | Null | Partition Key | Comment -------------------+---------+------+---------------+--------------------------------------------- _partition_id | bigint | true | false | Partition Id _partition_offset | bigint | true | false | Offset for the message within the partition _segment_start | bigint | true | false | Segment start offset _segment_end | bigint | true | false | Segment end offset _segment_count | bigint | true | false | Running message count per segment _key | varchar | true | false | Key text _key_corrupt | boolean | true | false | Key data is corrupt _key_length | bigint | true | false | Total number of key bytes _message | varchar | true | false | Message text _message_corrupt | boolean | true | false | Message data is corrupt _message_length | bigint | true | false | Total number of message bytes (11 rows) presto:tpch> SELECT _message FROM customer LIMIT 2; {"rowNumber":1,"customerKey":1,"name":"Customer#000000001","address":"IVhzIApeRb ot,c,E","nationKey":15,"phone":"25-989-741-2988","accountBalance":711.56,"marketSegment":"BUILDING","comment":"to the even, regular platelets. regular, ironic epitaphs nag e"} {"rowNumber":3,"customerKey":3,"name":"Customer#000000003","address":"MG9kdTD2WBHm","nationKey":1,"phone":"11-719-748-3364","accountBalance":7498.12,"marketSegment":"AUTOMOBILE","comment":" deposits eat slyly ironic, even instructions. express foxes detect slyly. blithel {"rowNumber":5,"customerKey":5,"name":"Customer#000000005","address":"KvpyuHCplrB84WgAiGV6sYpZq7Tj","nationKey":3,"phone":"13-750-942-6364","accountBalance":794.47,"marketSegment":"HOUSEHOLD","comment":"n accounts will have to unwind. foxes cajole accor"} {"rowNumber":7,"customerKey":7,"name":"Customer#000000007","address":"TcGe5gaZNgVePxU5kRrvXBfkasDTea","nationKey":18,"phone":"28-190-982-9759","accountBalance":9561.95,"marketSegment":"AUTOMOBILE","comment":"ainst the ironic, express theodolites. express, even pinto bean {"rowNumber":9,"customerKey":9,"name":"Customer#000000009","address":"xKiAFTjUsCuxfeleNqefumTrjS","nationKey":8,"phone":"18-338-906-3675","accountBalance":8324.07,"marketSegment":"FURNITURE","comment":"r theodolites according to the requests wake thinly excuses: pending”} presto:tpch> SELECT sum(cast(json_extract_scalar(_message, '$.accountBalance') AS double)) FROM customer LIMIT 10; _col0 ------------------- 6681865.590000002
Step 5: Add a topic decription file 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 etc/kafka/tpch.customer.json $ cat tpch.customer.json { "tableName": "customer", "schemaName": "tpch", "topicName": "tpch.customer", "key": { "dataFormat": "raw", "fields": [ { "name": "kafka_key", "dataFormat": "LONG", "type": "BIGINT", "hidden": "false" } ] }, "message": { "dataFormat": "json", "fields": [ { "name": "row_number", "mapping": "rowNumber", "type": "BIGINT" }, { "name": "customer_key", "mapping": "customerKey", "type": "BIGINT" }, { "name": "name", "mapping": "name", "type": "VARCHAR" }, { "name": "address", "mapping": "address", "type": "VARCHAR" }, { "name": "nation_key", "mapping": "nationKey", "type": "BIGINT" }, { "name": "phone", "mapping": "phone", "type": "VARCHAR" }, { "name": "account_balance", "mapping": "accountBalance", "type": "DOUBLE" }, { "name": "market_segment", "mapping": "marketSegment", "type": "VARCHAR" }, { "name": "comment", "mapping": "comment", "type": "VARCHAR" } ] } } $ 重启集群 $ presto/bin/presto-cli --server server1:9090 --catalog kafka --schema tpch presto:tpch> DESCRIBE customer; Column | Type | Null | Partition Key | Comment -------------------+---------+------+---------------+--------------------------------------------- kafka_key | bigint | true | false | row_number | bigint | true | false | customer_key | bigint | true | false | name | varchar | true | false | address | varchar | true | false | nation_key | bigint | true | false | phone | varchar | true | false | account_balance | double | true | false | market_segment | varchar | true | false | comment | varchar | true | false | _partition_id | bigint | true | false | Partition Id _partition_offset | bigint | true | false | Offset for the message within the partition _segment_start | bigint | true | false | Segment start offset _segment_end | bigint | true | false | Segment end offset _segment_count | bigint | true | false | Running message count per segment _key | varchar | true | false | Key text _key_corrupt | boolean | true | false | Key data is corrupt _key_length | bigint | true | false | Total number of key bytes _message | varchar | true | false | Message text _message_corrupt | boolean | true | false | Message data is corrupt _message_length | bigint | true | false | Total number of message bytes (21 rows) presto:tpch> SELECT * FROM customer LIMIT 5; kafka_key | row_number | customer_key | name | address | nation_key | phone | account_balance | market_segment | comment -----------+------------+--------------+--------------------+---------------------------------------+------------+-----------------+-----------------+----------------+--------------------------------------------------------------------------------------------------------- 1 | 2 | 2 | Customer#000000002 | XSTf4,NCwDVaWNe6tEgvwfmRchLXak | 13 | 23-768-687-3665 | 121.65 | AUTOMOBILE | l accounts. blithely ironic theodolites integrate boldly: caref 3 | 4 | 4 | Customer#000000004 | XxVSJsLAGtn | 4 | 14-128-190-5944 | 2866.83 | MACHINERY | requests. final, regular ideas sleep final accou 5 | 6 | 6 | Customer#000000006 | sKZz0CsnMD7mp4Xd0YrBvx,LREYKUWAh yVn | 20 | 30-114-968-4951 | 7638.57 | AUTOMOBILE | tions. even deposits boost according to the slyly bold packages. final accounts cajole requests. furious 7 | 8 | 8 | Customer#000000008 | I0B10bB0AymmC, 0PrRYBCP1yGJ8xcBPmWhl5 | 17 | 27-147-574-9335 | 6819.74 | BUILDING | among the slyly regular theodolites kindle blithely courts. carefully even theodolites haggle slyly alon 9 | 10 | 10 | Customer#000000010 | 6LrEaV6KR6PLVcgl2ArL Q3rqzLzcT1 v2 | 5 | 15-741-346-9870 | 2753.54 | HOUSEHOLD | es regular deposits haggle. fur (5 rows) presto:tpch> SELECT sum(account_balance) FROM customer LIMIT 10; _col0 ------------------- 6681865.590000002 (1 row) presto:tpch> SELECT kafka_key FROM customer ORDER BY kafka_key LIMIT 10; kafka_key ----------- 0 1 2 3 4 5 6 7 8 9 (10 rows)
5.5 System Connector 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 presto:default> SHOW SCHEMAS FROM system; Schema -------------------- information_schema metadata runtime presto:default> SHOW TABLES FROM system.runtime; Table --------- nodes queries tasks presto:system> use system.runtime; presto:runtime> show tables; Table --------- nodes queries tasks
6、启动Presto 1 2 3 4 5 6 7 8 9 10 11 12 [root@server1 presto]# bin/launcher start bin/launcher start –v 启动报错: Unsupported major.minor version 52.0,XXk需要1.8+ tar -zxvf software/XXk-8u45-linux-x64.tar.gz 主节点启动jps:bin/launcher start PrestoServer Worker启动:bin/launcher start PrestoServer
7、Command Line Interface 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 测试 Presto CLI https://repo1.maven.org/maven2/com/facebook/presto/presto-cli/0.100/presto-cli-0.100-executable.jar Download presto-cli-0.100-executable.jar并将其重命名为 presto-cli(你也可以重命名为 presto),然后添加执行权限。 mv presto-cli-0.100-executable.jar presto chmod +x presto ./presto --server server1:9090 --catalog hive --schema default presto:default> show tables; Table -------------------- order_test order_test_parquet 可以运行 --help 命令查看更多参数,例如你可以在命令行直接运行下面命令: ./presto --help ./presto --server server1:9090 --catalog hive --schema default --execute "show tables;" 默认情况下,Presto 的查询结果是使用 less 程序分页输出的,你可以通过修改环境变量 PRESTO_PAGER 的值将其改为其他命令,如 more,或者将其置为空以禁止分页输出。 [hsu@server1 ~]$ cat engines/presto-sql-cli.sh /home/hsu/presto/bin/presto-cli --server server1:9090 --catalog hive --schema default
8. 测试 XXbc 1 2 3 4 5 6 7 8 9 10 11 https://repo1.maven.org/maven2/com/facebook/presto/presto-jdbc/0.100/presto-jdbcbc-0.100.jar 使用 jdbc 连接 Presto,需要下载 XXbc 驱动 presto-jdbc-0.100.jar并将其加到你的应用程序的 classpath 中。 支持以下几种 JDBC URL 格式: jdbc:presto://host:port jdbc:presto://host:port/catalog jdbc:presto://host:port/catalog/schema 连接 hive 数据库中 sales 库,示例如下: jdbc:presto: http://server1:9090/hive/sales
9. 总结 1 2 3 4 5 6 本文主要记录 Presto 的安装部署过程,并使用 hive-hadoop2 连接器进行简单测试。下一步,需要基于一些生产数据做一些功能测试以及和 impala,spark-sql,hive 做一些对比测试。 资料:http://tech.meituan.com/presto.html http://prestodb.io/ http://www.dw4e.com/?p=141 http://wangmeng.us/notes/Impala/ #Impala Presto wiki 主要介绍了 Presto 的架构、原理和工作流程,以及和 impala 的对比。
二、orc优秀存储格式
https://code.facebook.com/posts/370832626374903/even-faster-data-at-the-speed-of-presto-orc/ https://github.com/klbostee/hadoop-lzo
#设置表格式1 2 3 4 set session hive.storage_format='RCBINARY' set session hive.storage_format='RCTEXT' set session hive.storage_format='ORC'; set session hive.storage_format='PARQUET';
三、Presto全靠优化参数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 presto: 官方默认存储格式是RCFile格式的,可以设置set session hive.storage_format='ORC'; XX:客户端就行了,先set session hive.storage_format='ORC';然后建的表就是ORC格式的了! XX:生成orc文件效率提升参数: presto:test> set session task_writer_count='8'; XX:cat jvm.config 我们这边 -Xmx120G XX: 出现数据倾斜: optimize_hash_generation,这个session 参数设置成true试下 presto:test> set session optimize_hash_generation='true'; Presto生成orc表: presto:default> set session hive.storage_format='PARQUET'; presto:default> create table test_parquet_test as select * from test_textfile; presto:default> set session hive.storage_format='ORC'; presto:test> set session task_writer_count='8'; presto:test> create table test_orc_test_presto as select * from test_textfile; hive (default)> show create table test; #生成不同格式的表 set session hive.storage_format='RCBINARY' set session hive.storage_format='RCTEXT' set session hive.storage_format='PARQUET'; set session hive.storage_format='ORC';
四、测试过程问题 1、某些查询维度不合理导致数据倾斜,某些节点负载过大而失去联系出现问题!1 2 3 具体表现为:Query 20150507_013905_00017_3b8jn failed: Encountered too many errors talking to a worker node. The node may have crashed or be under too much load. This is probably a transient issue, so please retry your query in a few minutes. select * from system.runtime.nodes;语句发现某些节点和集群失去联系导致识别! 解决:合理的查询维度,调优参数set session optimize_hash_generation='true';
2、orc文件格式生成效率低下1 2 3 4 5 6 XX:生成orc文件效率提升参数: presto:test> set session task_writer_count='8'; XX的生成orc就非常快,15个node,而我这里就算设置了调优参数,集群还是用了很长时间!就在硬件瓶颈上面!不同框架都有自己特定优化的格式,需要四组测试对比看,才能看到压缩空间情况!时间和空间是两难的抉择!XX:我们这边 -Xmx120G,set session task_writer_count='8', task.max-memory=30GB 每个节点写线程增加为8个,默认是1个!
3、presto目前无缓存功能1 新版本可能会提供,已经有人在开发次模块还没合并到官方master版本中,而只是在分支中!
4、presto计算节点失去联系,计算的orc结果文件非常巨大1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 presto:test> select count(1) from (SELECT a, b, c,row_number() OVER (PARTITION BY a,b ORDER BY a DESC) AS rnk FROM test_orc_test_presto) a where a.rnk=1; Query 20150507_062202_00117_3b8jn, FAILED, 9 nodes Splits: 18 total, 0 done (0.00%) 1:56 [88M rows, 1.27GB] [758K rows/s, 11.2MB/s] Query 20150507_062202_00117_3b8jn failed: Encountered too many errors talking to a worker node. The node may have crashed or be under too much load. This is probably a transient issue, so please retry your query in a few minutes. (http://135.33.5.63:9090/v1/task/20150507_062202_00117_3b8jn.2.1/results/20150507_062202_00117_3b8jn.1.6/864 - requests failed for 84.18s) presto:test> set session optimize_hash_generation='true'; SET SESSION presto:test> set session optimize_hash_generation='false'; SET SESSION 针对orc格式的表关闭了此调优参数,顺利执行!排查发现orc文件很大 需要控制生成更多比较小的orc结果文件!打一下这个patch,编译下presto-hive项目然后把presto-hive-0.100.jar替换了重启presto https://github.com/facebook/presto/pull/2655 ---- 目前我市0.100版本,而在0.101版本就已经修了此问题了! 确实用hive生成的orc表可以解决!难道某些节点文件太大,导致计算节点失去联系吗?YES,自问自答! QQ答疑: Ph-XX: hive生成的orc文件有很多,而presto生成的orc文件数和worker一样!导致查询orc的时候,某些节点失去联系而任务失败!presto查询hive生成的orc表很快完成!无报错!是0.100生成orc表的策略问题吧!@XX-AA XX-AA 2015/5/13 9:34:40 你可以设置task_write_count参数 XX-AA 2015/5/13 9:35:17 默认是1,也就是一个节点起一个write线程,也就是一个节点形成一个文件,如果这个参数设置多个,写的文件也会多 XX-AA 2015/5/13 9:35:22 写的效率也高
5、针对hive优化参数1 2 3 4 5 6 hive.metastore-cache-ttl etc/catalog/hive.properties hive元数据缓存的过期时间 default:1h hive.metastore-refresh-interval etc/catalog/hive.properties hive元数据缓存的刷新时间 default:1s optimizer.optimize-hash-generation 只需在Coordinator上etc/config.properties进行配置 表示是否启用对哈希聚合的优化,如果启用该选项,将会提升CPU使用率 default:FALSE SET SESSION optimize_hash_generation = 'true'; SET SESSION hive.optimized_reader_enabled = 'true';
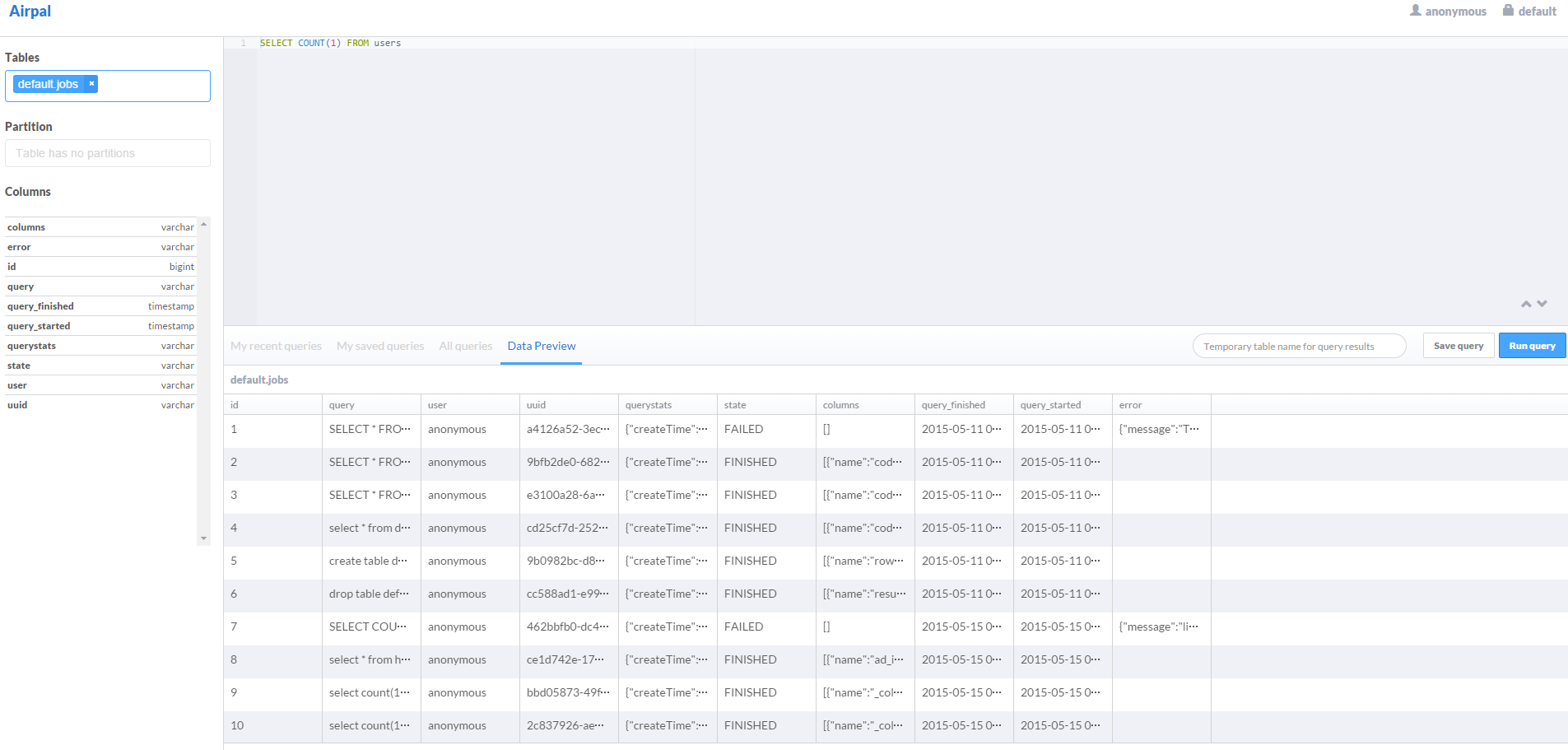
五、WEBUI界面 https://github.com/itweet/airpal
git clone https://github.com/itweet/airpal.git
配置后即可使用,参考文档进行!
Mysql创建库
1 2 3 4 5 6 7 8 9 10 11 12 mysql> select user,host from mysql.user\G; *************************** 1. row *************************** user: airpal host: % mysql> create database airpal; Query OK, 1 row affected (0.00 sec) mysql> grant all on airpal.* to 'airpal'@'%' identified by 'airpal'; Query OK, 0 rows affected (0.00 sec) mysql> flush privileges; Query OK, 0 rows affected (0.00 sec)
配置reference文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 [hsu@server1 airpal]$ cat reference.yml # Logging settings logging: loggers: org.apache.shiro: INFO # The default level of all loggers. Can be OFF, ERROR, WARN, INFO, DEBUG, TRACE, or ALL. level: INFO # HTTP-specific options. server: applicationConnectors: - type: http port: 8081 idleTimeout: 10 seconds adminConnectors: - type: http port: 8082 shiro: iniConfigs: ["classpath:shiro_allow_all.ini"] dataSourceFactory: driverClass: com.mysql.jdbc.Driver user: airpal password: airpal url: jdbc:mysql://127.0.0.1:3306/airpal # The URL to the Presto coordinator. prestoCoordinator: http://server1:9090
migragte your database
1 2 3 4 [hsu@server1 airpal]$ java -Duser.timezone=UTC -cp build/libs/airpal-0.1.0-SNAPSHOT-all.jar com.airbnb.airpal.AirpalApplication db migrate reference.yml INFO [2015-05-11 03:50:19,945] org.flywaydb.core.internal.command.DbMigrate: Successfully applied 5 migrations to schema `airpal` (execution time 00:01.568s). [hsu@server1 airpal]$ java -server -Duser.timezone=UTC -cp build/libs/airpal-0.1.0-SNAPSHOT-all.jar com.airbnb.airpal.AirpalApplication server reference.yml
六、TPC-H 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 http://prestodb-china.com/docs/current/installation/benchmark-driver.html https://repo1.maven.org/maven2/com/facebook/presto/presto-benchmark-driver/0.103/presto-benchmark-driver-0.103-executable.jar $ mv presto-benchmark-driver-0.103-executable.jar presto-benchmark-driver $ chmod +x presto-benchmark-driver [hsu@server1 test]$ ls presto-benchmark-driver $ cat suite.json { "file_formats": { "query": ["single_.*", "tpch_.*"], "schema": [ "tpch_sf(?<scale>.*)_(?<format>.*)_(?<compression>.*?)" ] }, "legacy_orc": { "query": ["single_.*", "tpch_.*"], "schema": [ "tpch_sf(?<scale>.*)_(?<format>orc)_(?<compression>.*?)" ], "session": { "hive.optimized_reader_enabled": "false" } } } #开始测试,木有成功 [hsu@server1 test]$ sh presto-benchmark-driver --server server1:9090 --catalog tpch--schema default https://prestodb.io/docs/current/connector/tpch.html $ cat tpch.properties connector.name=tpch $ /home/hsu/presto/bin/presto-cli --server server1:9090 --catalog tpch presto:default> SHOW SCHEMAS FROM tpch; Schema -------------------- information_schema sf1 sf100 sf1000 sf10000 sf100000 sf300 sf3000 sf30000 tiny presto:default> use sf1; presto:sf1> show tables; Table ---------- customer lineitem nation orders part partsupp region supplier
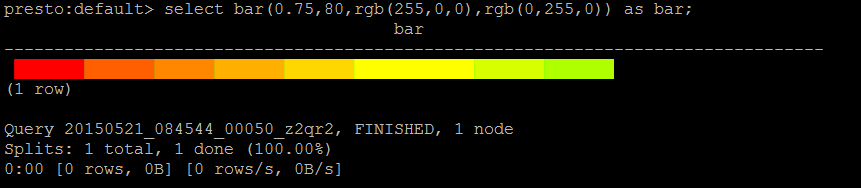
七、函数 1 http://prestodb-china.com/docs/current/functions/color.html
时间函数1 2 3 4 5 6 7 8 9 10 11 12 13 presto:default> select '2001-08-22 03:04:05',date_format(cast('2001-08-22 03:04:05' as timestamp),'%H%m') from default.event_type_jf limit 1; _col0 | _col1 ---------------------+------- 2001-08-22 03:04:05 | 0308 (1 row) http://prestodb-china.com/docs/current/functions/datetime.html presto:default> select '2001-08-22 03:04:05',date_format(cast('2001-08-22 03:04:05' as timestamp),'%Y%m%d') from default.event_type_jf limit 1; _col0 | _col1 ---------------------+---------- 2001-08-22 03:04:05 | 20010822 (1 row)
八、join性能 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 join时有大表的话开启distributed-joins-enabled=true,并将大表放在join的右侧,会提高性能 或者命令行里面set session distributed_join='true'; 配置文件 # sample nodeId to provide consistency across test runs node.id=ffffffff-ffff-ffff-ffff-ffffffffffff node.environment=test http-server.http.port=8080 discovery-server.enabled=true discovery.uri=http://localhost:8080 exchange.http-client.max-connections=1000 exchange.http-client.max-connections-per-server=1000 exchange.http-client.connect-timeout=1m exchange.http-client.read-timeout=1m scheduler.http-client.max-connections=1000 scheduler.http-client.max-connections-per-server=1000 scheduler.http-client.connect-timeout=1m scheduler.http-client.read-timeout=1m query.client.timeout=5m query.max-age=30m plugin.bundles=\ ../presto-raptor/pom.xml,\ ../presto-hive-cdh4/pom.xml,\ ../presto-example-http/pom.xml,\ ../presto-kafka/pom.xml, \ ../presto-tpch/pom.xml presto.version=testversion experimental-syntax-enabled=true distributed-joins-enabled=true
队列相关 https://prestodb.io/docs/current/admin/queue.html
SQL语法 1.3 显示分区表 1 presto:bigdata> SHOW PARTITIONS FROM test_partitioned;
Presto for ambari
参考:https://prestodb.io/