SQL on Hadoop TPCDS性能测试
本测试,重点性能测试4个维度,测试对象为主流SQL on Hadoop性能表现,为技术选型做一些参考,由于硬件资源有限,本测试数据集比较小,前提是所有数据保证都能装载到内存.
内容还涉及到了SQL on RDBMS 和 SQL on NOSQL性能测试。对一些特殊场景的应用参考。企业级数据仓库解决方案,特别是分析性场景慢慢会被SQL on Hadoop逐渐替代,而且SQL on Hadoop逐渐成熟,可以支持类似Oracle PL/SQL功能。Hive 2.0 已经支持Hive HPL/SQL已经集成,支持存储过程,Impala,SparkSQL也能支持。后两者支持的还不够成熟.
SQL on Hadoop在未来会在数据仓库占有非常重要的位置,所以很多传统数据仓库方案慢慢被替代,HadoopDBA职位也会发展起来。SQL on NOSQL(NewSQL)也会替代一部分应用场景。所以技术选型性能测试,为企业选择最有利的SQL on Hadoop架构,构建一栈式大数据解决方案非常重要的一环。
Prerequisites
- Hadoop2.x or later cluster
- Hive 1.1(Tez)
- Impala 2.2
- Presto 0.143
- Drill 1.6
SparkSQL 1.6.1 and 1.5.2
测试环境4台物理机
- server1 : CPU total : 32 ; mem total : 126 g ; disk hdfs: 22.4 TiB
- server2 : CPU total : 32 ; mem total : 126 g ; disk hdfs: 7.7 TiB TiB
- server3 : CPU total : 8 ; mem total : 32 g ; disk hdfs: 500.7 GiB TiB
- server4 : CPU total : 8 ; mem total : 32 g ; disk hdfs: 500.7 GiB TiB
Compile and package the appropriate data generator.
1 | $ git clone https://github.com/hortonworks/hive-testbench.git |
Generate and load the data.
1 | $ tar -zxvf hive-testbench.tar.gz |
Run queries.
1 | Hive-tpcds testing: |
SQL-on-Hadoop性能测试结果
Textfile
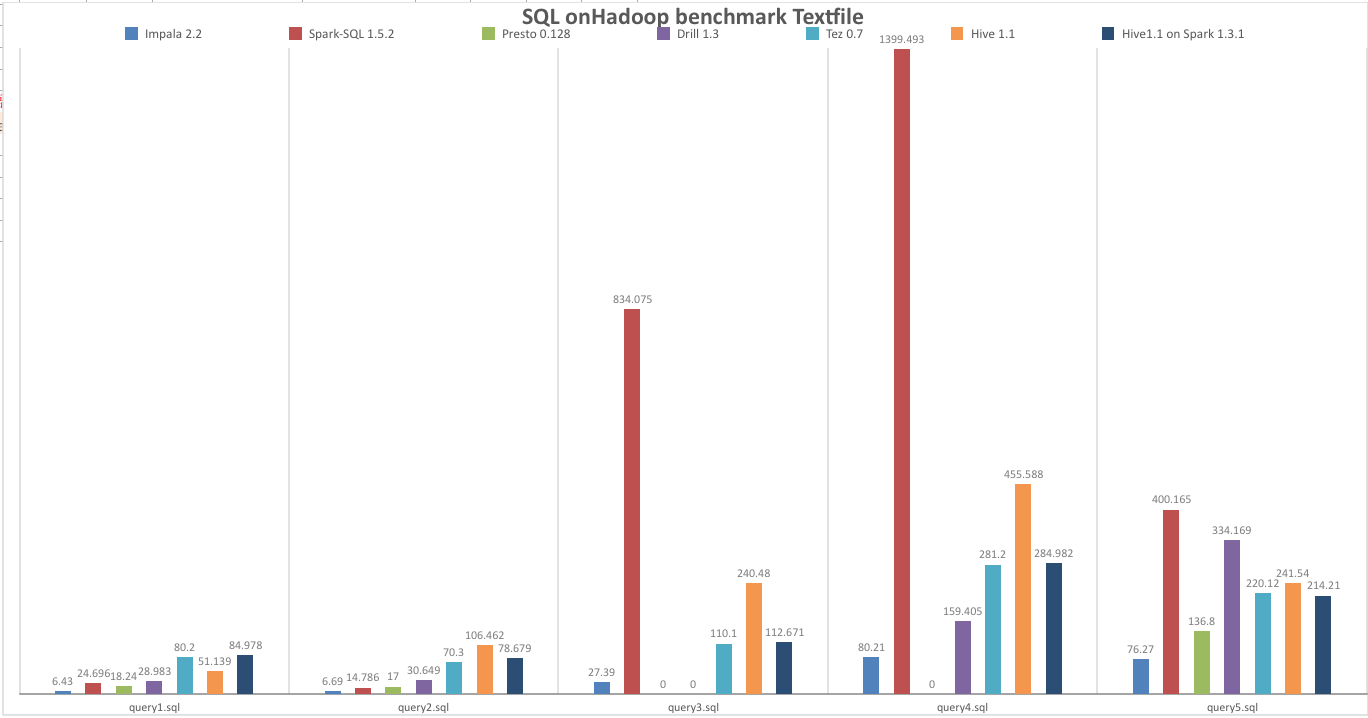
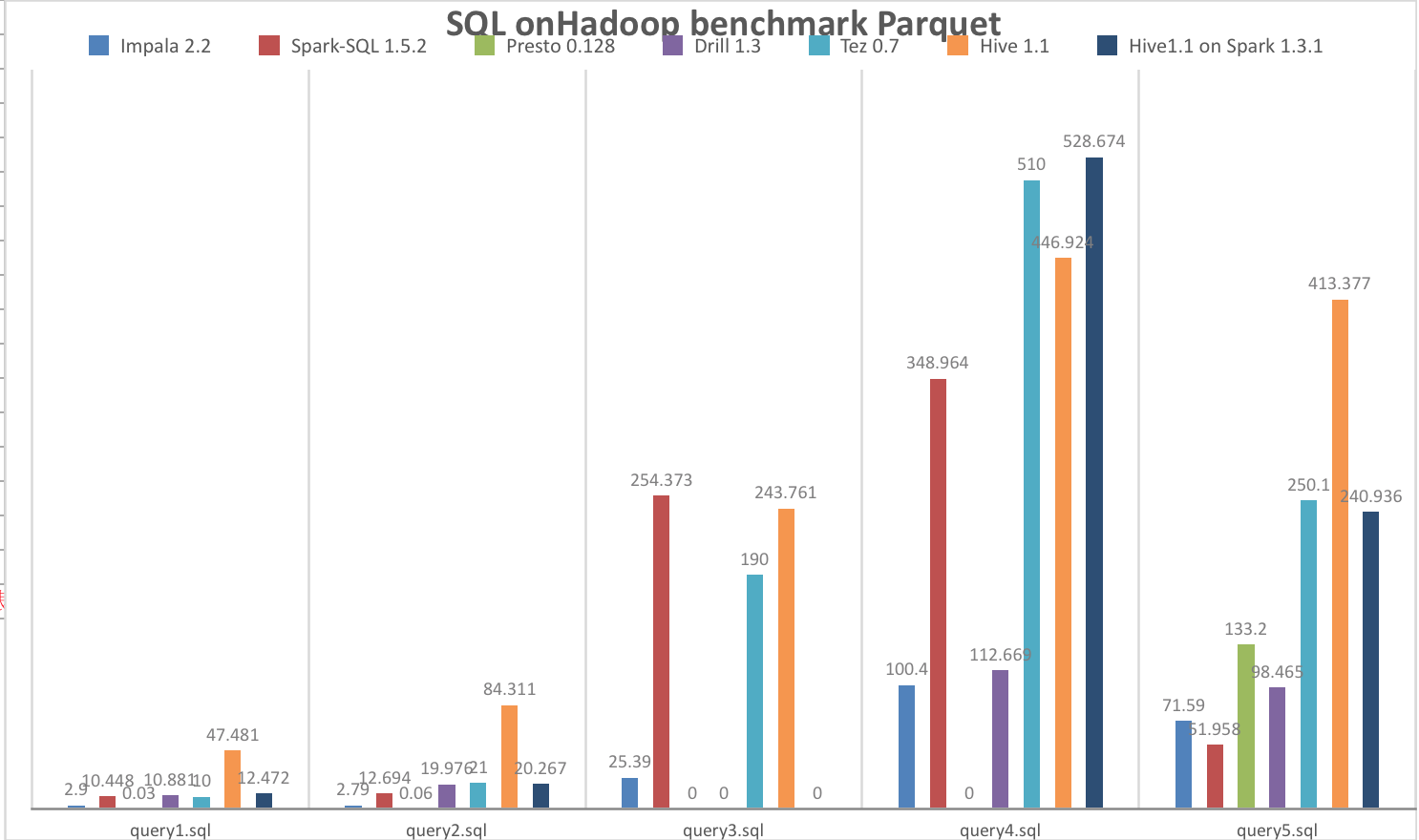
执行时间为0s,说明语法不支持,0.1执行失败,有些是框架本身不稳定(Hive on Spark && Presto)Parquet
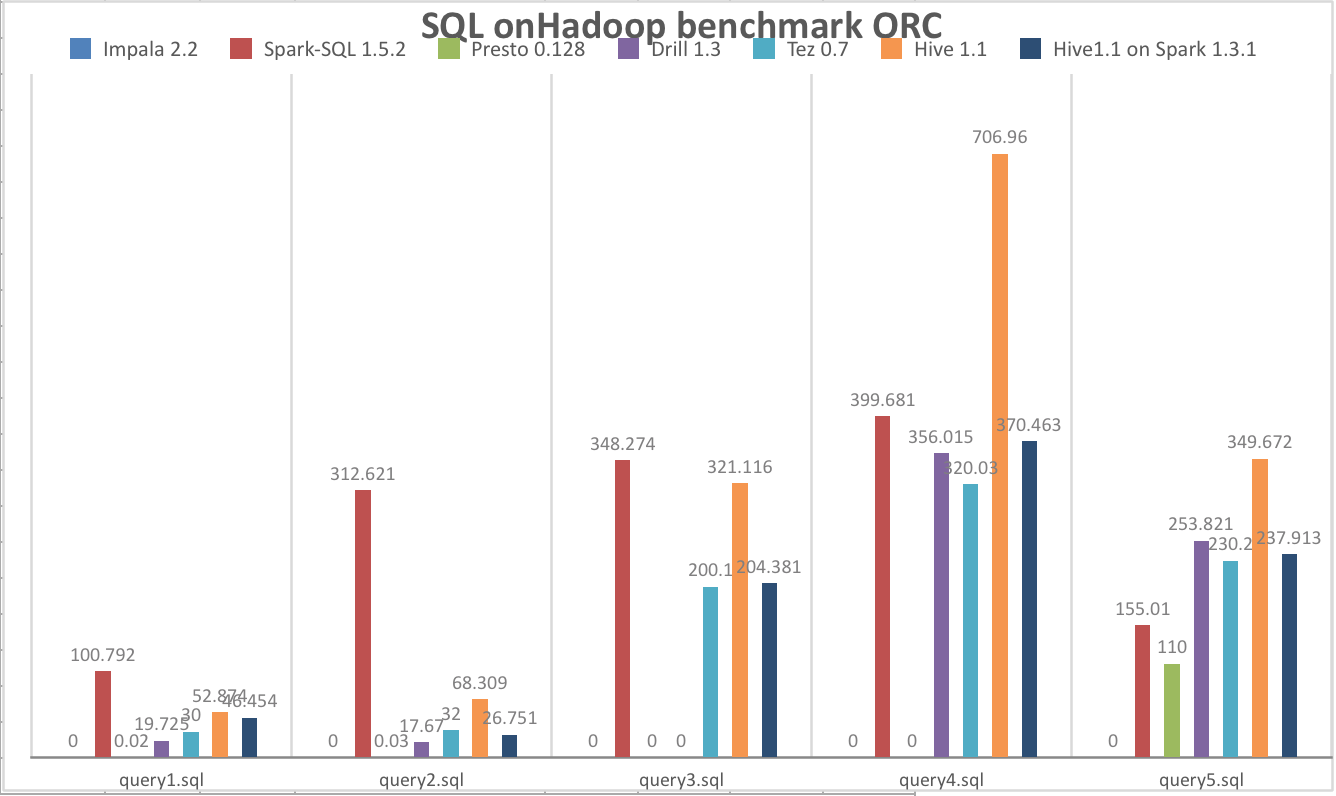
执行时间为0s,说明语法不支持,0.1执行失败,有些是框架本身不稳定(Hive on Spark && Presto)ORC
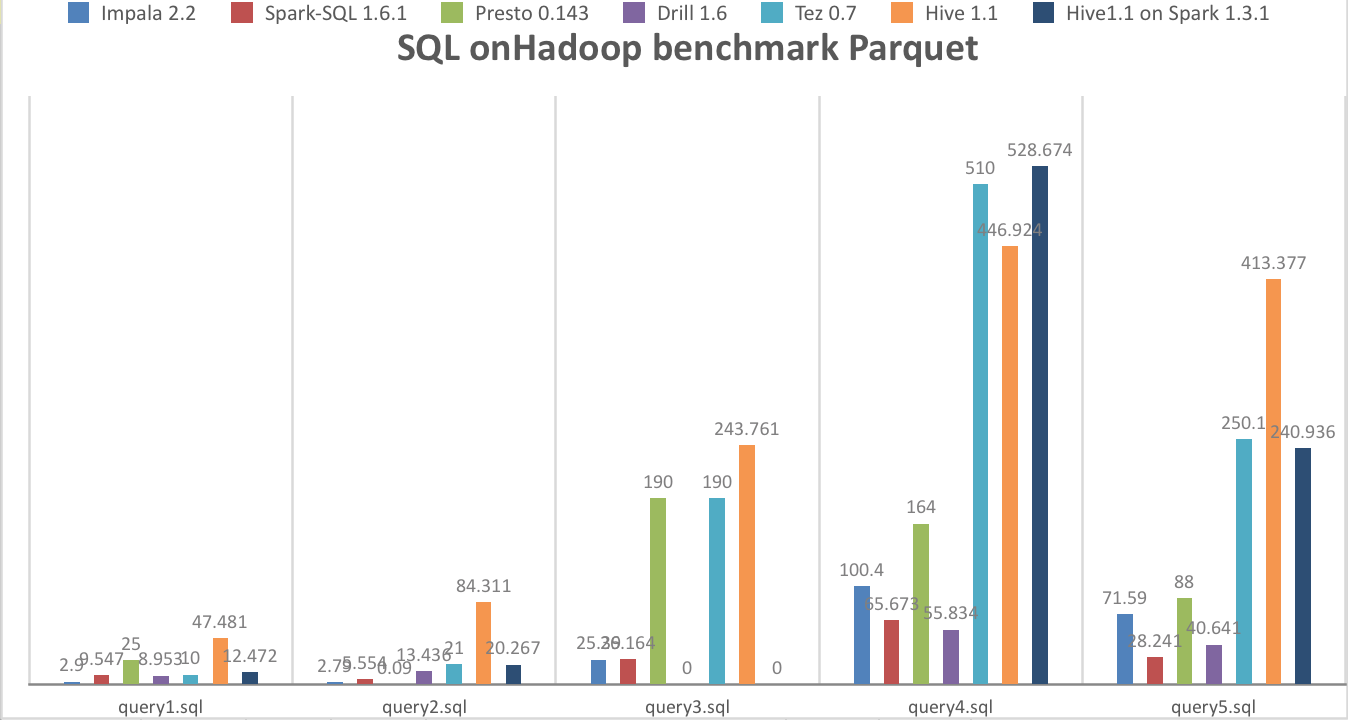
执行时间为0s,说明语法不支持,0.1执行失败,有些是框架本身不稳定(Hive on Spark && Presto)Parqeut(new version)
执行时间为0s,说明语法不支持,0.1执行失败,有些是框架本身不稳定(Hive on Spark && Presto)
SQL on NOSQL性能测试结果
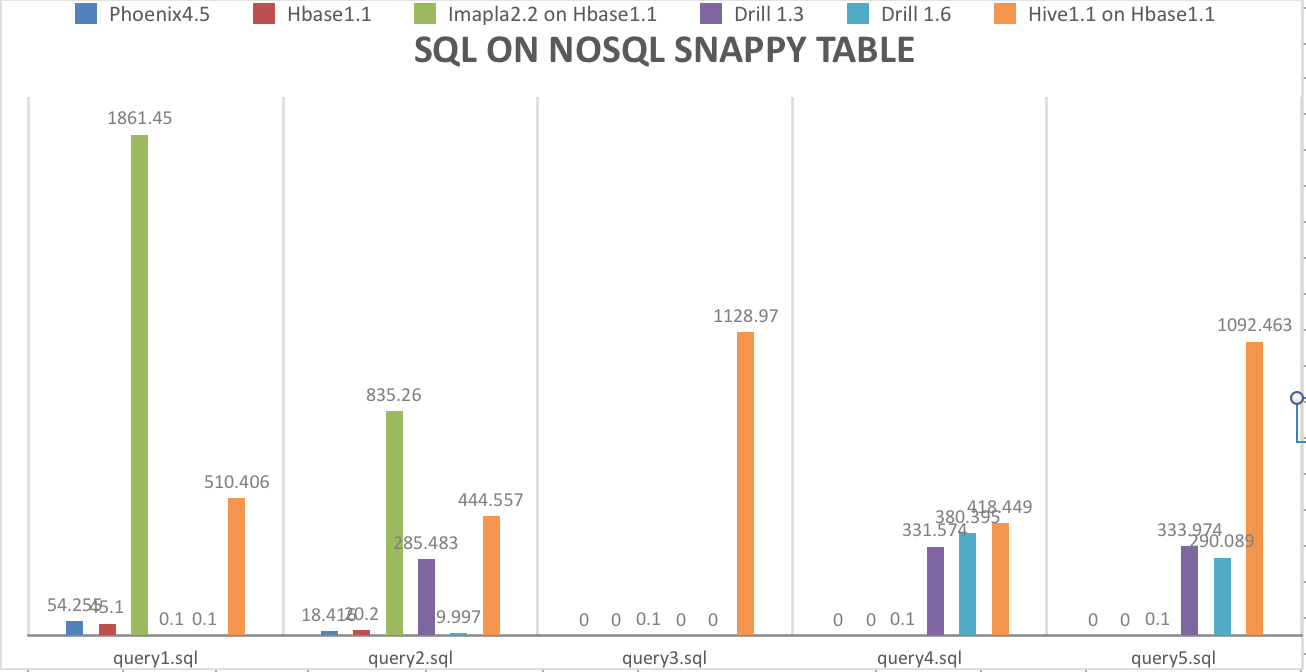
执行时间为0s,表示语法不支持,0.1执行失败;这里测试数据在6000万左右。
1
2
3
4
5
6
Comparison between compression algorithms
Algorithm % remaining Encoding Decoding
GZIP 0.134 21 MB/s 118 MB/s
LZO 0.205 135 MB/s 410 MB/s
Zippy/Snappy 0.222 172 MB/s 409 MB/s
列式存储
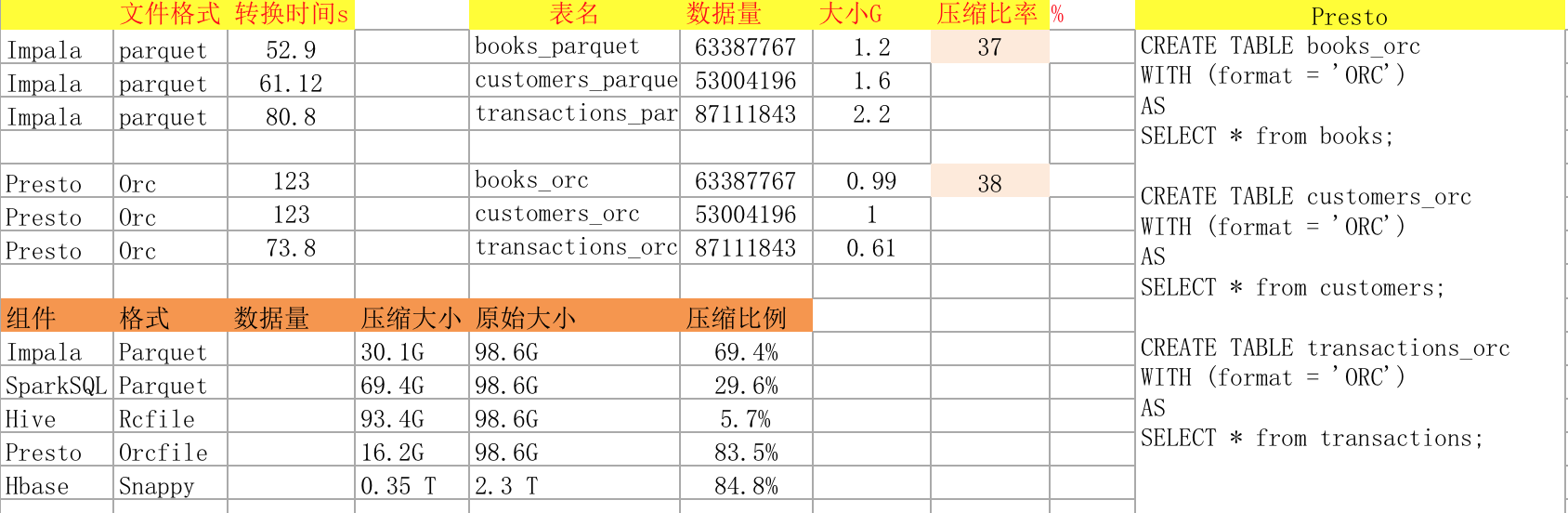
执行query和测试数据源
SQL-on-Hadoop && SQL-on-NOSQL && SQL on Hadoop Join RDBMS/NOSQL
SQL-on-Hadoop && SQL-on-NOSQL && SQL on Hadoop Join RDBMS/NOSQL 脚本文件
总结
1、为了公平公正,SQL是完全在多种SQL on Hadop框架能正常执行的,在某些框架,无法执行成功,由于语法有细微区别,不支持导致执行时间为0
2、其他情况导致执行时间为0.1,因为框架本身不够稳定(worker节点失去联系),执行失败,多数SQL on Hadoop框架可以很快执行完成。
3、Presto使用效率确实很不错,但是需要做很多优化参数和底层文件大小考虑,还有一些内存有关参数调节,而且节点压力太大会失去联系,技术性公司出的东西,对orc格式优化最多性能最优。
4、Hive查询hbase表,因为mapjion优化参数导致报错问题?
1
2
3
4
5
6
7hive (default)> set hive.auto.convert.join;
hive.auto.convert.join=true
hive (default)> set hive.auto.convert.join=false;
hive (default)> set hive.ignore.mapjoin.hint;
hive.ignore.mapjoin.hint=false
hive (default)> set hive.ignore.mapjoin.hint=true;
hive 跑join的时候,由于做了优化,忽略mapjoin这种写法,而交给框架自动判断是否mapjoin,发现读取hbase表做join操作,都给转换为mapjoin了,导致内存报错,把自动检测转换mapjoin参数关闭后能正常跑完。1
2
3Execution log at: /tmp/hadoop/hadoop_20160403103939_1ee1a162-fa4b-425a-a0ad-f3aaa121e9d1.log
2016-04-03 10:39:29 Starting to launch local task to process map join; maximum memory = 2025848832
2016-04-03 10:39:38 Processing rows: 200000 Hashtable size: 199999 Memory usage: 571202024 percentage: 0.282
5、SQL-on-Hbase,Hbase+phoenix方案可以执行CRUD,简单事物,保证数据最终一致性,支持完整的事物,完全继承Hbase的权限;场景,Salesforce开源的基于HBase的SQL查询系统。基本原理是将一个对于HBase client来说比较复杂的查询转换成一系列Region Scan,结合coprocessor和custom filter在多台Region Server上进行并行查询,汇总各个Scan结果。种种迹象表明,Phoenix应该不是个优化的OLAP系统,更像是一个用于简单单表查询,过滤,排 序,检索的OLTP系统。
测试总结:5.1、为了保证查询尽量分布布到多台服务器,Regions的个数一定要保证分散。
5.2、为了保证数量不会太大,需要建立snappy表,并且保证regions数量多的同时,尽量分散到多台服务器,row_key设计很关键,表压缩保证数据量不会太大,而导致regions大多数时间处于Compaction状态,影响使用性。
5.3、一个region尽量保证在1G大小,默认10G进行split。测试的时候发现如果所有数据集中在一个region,查询就在哪一个节点,无法发挥分布式的优势,而且还有查询不动的倾向,甚至报错。手动做了compaction && split后,1个regions变成3个,不仅能查询,而且快速返回结果。
5.4 除phoenix方案,之外的其它方案,无法用到hbase的优化器,级别是scan数据到框架内部作处理,这样的缺点是,读取数据耗费太多时间,就是把hbase当做一个后端数据存储系统。而不是一个nosql数据库。性能提升比较难做,瓶颈在regionserver读取数据上,如果是海里数据写出,其它sql on hadoop框架scan读取都是全表扫描,那么对hbase集群压力非常大。无法完全发挥hbase作为一个nosql数据库的优势。
6、在测试中,测试了spark sql 两个版本,非常可喜的事,在spark1.6+版本基本解决了gc严重,shuffle效率低下的问题,join查询一下子有了质的飞跃,具体请参看性能测试图表内容。两个spark版本性能差距非常大,而去同样的sql,同样的硬件环境和数据量。
7、其次apache drill表现也蛮让人眼前一亮的,而且plugin支持度很大,对nosql,rdbms,sql on hadoop等主流数据源都有很好的支持,虽然和prestodb有一定的重合度,但是比presto性能好一些,而且稳定得多,特别对hbase数据源的查询,效率也仅次于phoenix,具体可以看测试结果。
以上做了一点总结,由于个人水平有限,难免错漏,还望大家多多反馈。以便我不断修正自己的认知。