Why Spark RDD
我提出的论文计划,一再被打乱,我也在找机会慢慢调整过来。
今天,我们聊一聊Spark,我第一次在工作中使使用spark是0.9版本,当时是试用Spark来做OLAP Cube模型,那个时候的SparkSQL称为Shark,历史原因,spark 1.0以后的版本被SparkSQL取代,shark可能很多人都没怎么听说过。
我去研究试用spark是被社区疯狂的宣传打动的,但是确实也能解决一些MapReduce、Hive小数据级响应慢的问题,而宣传一直以来都比较夸大,在很长一段时间里Spark都是极其不稳定的分布式系统,只能说Spark比较会做社区,技术上解决了部分实际问题。
今天,再回头看看《An Architecture for Fast and General Data Processing on Large Clusters》。
弹性分布式数据集(RDDs) 是 Spark 中的核心基础,它是MapReduce模型一种简单的扩展和延伸。
MapReduce模型缺陷:在并行计算阶段之间能够高效地数据共享。
Spark运用高效的数据共享概念和类似于 MapReduce 的操作方式,实现高性能的数据处理能力。
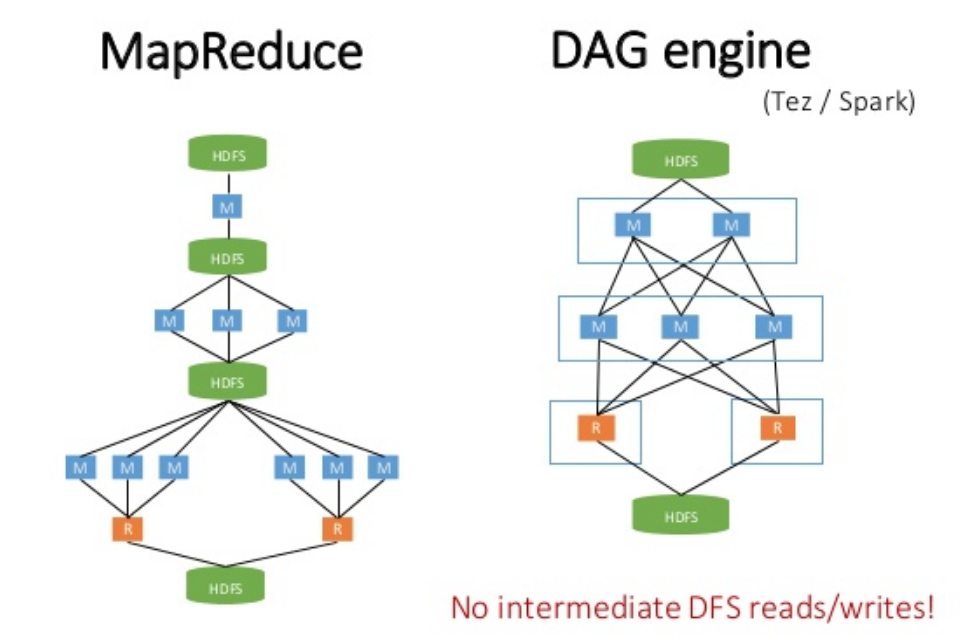
整个Spark作业每个作业都会生成DAG,对DAG进行优化,可以加快数据处理效率,在DAG中流转的数据就是RDDs,每一个数据变换的操作就是直接操作的RDDs。
通过将计算转换为一个有向无环图DAG,可以高效率的重复执行DAG里某些计算失效的任务达到容错。
RDDs 是一个可以避免复制的容错分布式存储数据集,每一个RDD 都会记住由构建它的那些操作所 构成的一个图,类似于批处理计算模型,可以有效地重新计算因故障丢失的数据。
当一个RDD的某个分区丢失的时候,RDD记录有足够的信息记录其如何通过其他的RDD进行计算,且只需重新计算该分区。因此,丢失的数据可以被很快的恢复,而不需要昂贵的复制代价。
Spark核心:
- 计算阶段数据共享,DAG直接可通过RDD进行高效率的数据共享
- 极低的代价重算故障任务,不需要与任何外部存储交互
- DAG Engine,高效率容错和优化计算
- 分布式系统忌讳大量网络IO,RDD高度压缩,部分任务失败容错回滚,不会导致重算,减少网络IO
在实际工作中,MapReduce、spark相互配合完成工作,场景选型不同的技术。
今年我们Spark+AI,转型的Spark是否能追上如火如荼的AI领域呢?
我们,拭目以待吧。